.net 代码混淆原理性实践
现在我们已经很清楚,托管PE文件可以轻而易举的被反编译,如果您想源代码不被使用者通过反编译的方式获得,该使用哪种保护手段呢?
借鉴传统Windows应用程序防止被反汇编的做法,我们也可以采用代码混淆和对应用程序集加壳的方法。关于程序集加壳的内容我会在下一篇文章中讨论。
代码混淆,简单的说就是使用名称替换、字符串加密等手段使得我们最初的代码面目全非,从而使破解者即使能能成功获得IL代码也很难得到想要的源代码。代码混淆常用的方式有名称混淆、流程混淆和语法混淆。
9.3.1 名称混淆
在讲解名称混淆的原理之前,我们先建一个用于测试的控制台程序,如代码清单9-8所示。
代码清单9-8 名称混淆测试代码
class Program
{
static void Main(string[] args)
{
string userID="asldjf3333djf";
string pwd = GetPassword(userID);
ChangeInfo(userID, pwd);
}
public static string GetPassword(string userID)
{
return "123456";
}
public static void ChangeInfo(string userID,string pwd)
{
}
}
代码清单9-8中的代码很简单,包含了三个函数Main函数、GetPassword函数和ChangeInfo函数。从函数的名称和参数中,我们很容易想到其含义。接下来,编译项目,然后使用Reflector打开生成的EXE文件,查看Program类的IL代码。如图9-14所示。
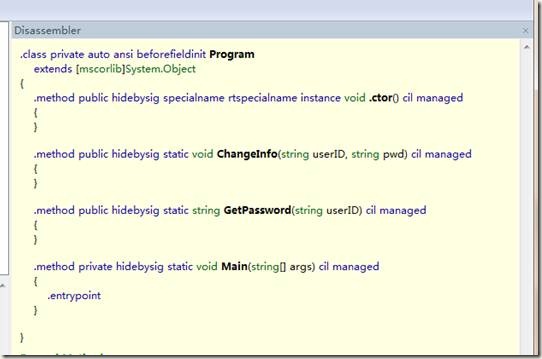
图9-14 Program类的IL代码
下面我们使用PE文件查看工具CFF载入可执行文件。定位到#Strings流,如图9-15所示。当前程序集的类型、引用类型、成员等的定义都在该字符串中。

图 9-15 Program.exe 的#Strings流
下面我们使用CFF来修改#Strings流的内容。查找到字符串“ChangeInfo”和字符串“GetPassword”,随意替换,然后运行程序验证是否有问题。
那么这样的修改有什么作用呢,我们保存修改后,使用Reflector重新打开exe文件,如图9-16所示。
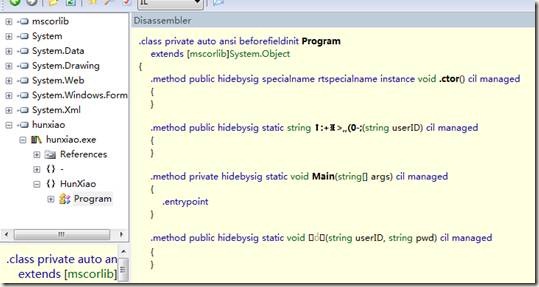
图9-16 修改#Strings流后的IL代码
从9-16中,我们可以看到,先前的ChangeInfo和GetPassword方法名已经被替换成不可识别的乱码。
在完整的实践上面的演示之后,我想告诉你的是,你已经明白了名称混淆的原理。现在简单的总结一下,所谓.NET名称混淆就是修改#Strings流内特定字符串,使其不能 被轻易辨认。上面的例子只修改了两个方法的名称,当然我们可以修改包括在变量在内的所有名称来迷惑“对手”。如果您要问我,如果一个大型的软件项目,这样手动修改可行吗?当然不可行,但是原理知道了,编写这样一个工具并非难事。当然现在已经出现很多成熟的名称混淆工具,这里就不给您一一介绍了。
明白了原理之后,我们再看字符串替换的方式到底有哪些。
第一种替换方法为无意义替换。我们知道在实际的开发过程中,我们都必须遵守一定的命名规范来为类型、属性、字段命名。但是当我们对编译成功的代码进行名称混淆的时候就是要将这些规范的、规律的名称变得毫无意义,毫无规律可循。
第二种替换方法称为不可打印字符替换。在UNICODE字符集中,一些特殊字符,目前无法得到正确的显示,比如从0x01到0x20之间的字符。如果把名称替换成这些字符,显示出来的就是奇怪的乱码。
第三种替换方法为空字符替换。空字符替换就是把名称替换为空串。但是这种方法并不适合实际的应用,因为如果名称都为空,那么势必要产生二义性。
在实际环境中,我们常常要引用其他程序集。如果被引用的程序集的方法名称没有被混淆的话,那么在本程序集中混淆引用的方法名是无效的,会引发调用异常。这是名称混淆最大的局限性。
 QQ:147399120
QQ:147399120
QQ:147399120
QQ:147399120
QQ:147399120
QQ:147399120
© Copyright( 2008-2012) Web.QhWins.Com All Rights Reserved 西宁威势电子信息服务有限公司(威势网络)版权所有,未经书面制授权,请勿随意转载!